Changelog
Follow up on the latest improvements and updates.
RSS
new
Quarterly Release
Announcing Amperity’s Spring Launch '26
Audience monetization
NEW:
The Audience monetization page is available for monetizing UID 2.0-based audiences in The Trade Desk Data Marketplace.Customer Data Agent
NEW:
The Customer Data Agent helps you move from intent to action through natural language conversation to create segments, build journeys, and explore customer data.Predictive Modeling UI
NEW:
The Predictive Modeling UI has a new setup process for the predicted customer lifetime value model and product affinity model so users can now self-serve and iterate on their predictive models.Identity resolution summary
UPDATED:
The Identity resolution summary page shows the outcome of identity resolution, including identity changes over time, matching strategies, and identity complexity.Labels available in filters
new
Quarterly Release
Announcing Amperity’s Fall Launch '25
Our Fall 2025 Quarterly Launch is here! In this release we are unveiling Real-Time Profiles, a complete customer view that combines Amperity’s AI-powered identity resolution with real-time event streaming.
Review the full announcement or read on for a summary of key updates along with more detailed descriptions. Here's a summary of the features released:
- Real-Time Profiles
- Event-Triggered Journeys
- In-Session Personalization
- Custom Segment Metrics
- Outbound Bridge for BigQuery
- Bring Your Own Storage (BYOS) for Azure
What Are Real-Time Profiles?
For the first time, brands can recognize customers instantly and respond in the moment with full context. Every booking, click, loyalty update, or on-property interaction updates instantly, so every touchpoint connects back to the customer’s full history.
Our product team spent the summer enhancing our customer data cloud to enable real-time profiles. Read about the details here.
In summary, live customer signals flow through event streams directly into Amperity's AI-Powered Customer Profiles the moment they occur, often within milliseconds of ingestion. These are saved as custom attributes on the profile, like
Recently Abandoned Cart
or Birthday Approaching
. The result is a continuously updated profile that's both complete and instantly actionable.Real-time profiles are currently available by request only. Please reach out to your customer success rep if you are interested.
What Real-Time Profiles power in the Fall 2025 release
Event-Triggered Journeys
- React to customer actions as they happen, up to the sub-second. Event-Triggered Journeys let marketers trigger personalized experiences based on complete customer context, not just isolated events. Recover abandoned carts, deliver upgrade offers at check-in, or send tailored pre-trip messages using real-time signals.
In-Session Personalization
- Adapt websites, apps, and offers mid-session as new customer data flows in. Use real-time profile updates to personalize sort order, bundles, and messaging based on loyalty tier, purchase history, and current browsing behavior up to sub-second. All while the customer is still engaged.
Additional Fall enhancements
Custom Segment Metrics
- Define and track the metrics that matter most, from lifetime value and purchase frequency to loyalty engagement.
- Docs
Amperity Bridge for BigQuery
- Amperity Bridge is now available for BigQuery Outbound (Inbound from BigQuery to Amperity was already available). This is a native data sharing integration that uses Google’s BigQuery Sharing for fast and secure access, without copying data or managing ETLs.
- Docs | Training
Bring Your Own Storage (BYOS) for Azure
new
Quarterly Release
Announcing Amperity’s Summer Release '25
Our Quarterly Release is here - Summer '25! In this release we are introducing major enhancements across orchestration, segmentation, and data activation.
Review the full announcement or read on for a summary of key updates along with more detailed descriptions. Here's a summary of the features released:
- Campaigns are now Activations and Other Improvements
- Destination Improvements and UI Updates
- Amperity Journeys
- Segments AI Assistant
- Profile API
- Real-Time Tables
- Amperity Bridge for BigQuery
- Amps Alerting
Campaigns are now Activations and Other Improvements
- Please note that the “Campaigns” tab has now been renamed the “Activations” tab.Campaigns can now run every 3 hours and Orchestrations every 15 minutes, allowing for more frequent connection with your customers. Scroll to the bottom to see how you can find your campaigns.
- Docs
Destination Improvements and UI Updates
- Please note that Orchestrations will be moved from within the "Destinations" tab to the new "Activations" tab. This change will roll out over the next weekDestinations have also been improved to deliver a more intuitive self‑service, guided UI, and setup process for outbound data workflows. Scroll to the bottom to see how you can find your orchestrations.
- Docs | | Training
Amperity Journeys
- Journeys is a visual, no‑code canvas that lets you map and execute complex cross‑channel workflows. Whether it is a time‑sensitive customer experience like reminder emails or running sophisticated multi‑variant marketing tests across multiple channels, Journeys adapts to your use case and integrates with existing personalization tools. Journeys can run as often as every 3 hours.
- Docs | Training
Segments AI Assistant
- The new AI Assistant for Segments powers both technical and non-technical team members to quickly create and edit visual segments using natural language. Launch more campaigns and get insights faster.
- Docs | Training
Profile API
- Profile API now provides a more intuitive, scalable, and cost-effective way to find customer profiles through flexible, multi-criteria search to power real-time personalization and customer service, even with inconsistent identifiers.
- Docs | Overview Training
Real-Time Tables
- Now generally available, Real-Time Tables deliver live customer events into Amperity for instant segmentation and activation.
- Docs | Overview Training
Amperity Bridge for BigQuery
- Amperity Bridge is now available for BigQuery (just inbound from BigQuery to Amperity for now). This is a native data sharing integration that uses Google’s BigQuery Sharing for fast and secure access, without copying data or managing ETLs.
- Docs
Amps Alerting
- Amps Alerting is a new feature that allows you to set alerts and thresholds to monitor your Amps consumption. This only applies if you are on the Amps Consumption-based pricing.
How to find Campaigns in the Activations tab:
To find campaigns in the current experience, you must click the “Activations” tab and then select the “Campaigns” sub-tab.

How to Find Orchestrations once tenant is updated:
1) Orchestrations will no longer be found in the "Destinations tab" and the main sub-tab has been renamed “Destinations." Now this sub-tab only contains destinations you’ve set up.

2) Once your tenant is set up, you will find orchestrations in the "Activations" tab.

new
Quarterly Release
Announcing Amperity’s Spring Release '25
Our inaugural Quarterly Release is here - Spring '25! We are adopting a seasonal release cadence to give you a more predictable and impactful product experience.
Review the full announcement or read on for a summary of key updates along with more detailed descriptions:
- Stitch Benchmarking
- Operational Identities
- Activation IDs
- Run Workflow API
- Complex Types in Source Data Supported
- Snowflake Outbound Bridge
Stitch Benchmarking
The Stitch Benchmarking UI allows Datagrid Administrators to understand how well Stitch is performing both in a run state and during implementation. It reduces time-to-value by allowing users to quickly configure Stitch and continue to iterate over time. Once Stitch configuration is complete, Datagrid Administrators can understand Stitch performance over time and make configuration changes as needed to maintain a high level of performance.
Operational Identity
Set up rules-based identity resolution that supports broader operational use cases that require stricter matching criteria, like loyalty or clienteling, with precise control over how customer records are matched and merged across your data sources.
Activation IDs
Target and segment customers using the identifier that best fits your needs (e.g., loyalty ID, order ID, or any other unique identifier). This capability delivers more precise audience segmentation and campaign targeting by allowing flexible identity selection tailored to your specific campaign goals, eliminating the need to share comprehensive universal identities for activation when specific identifiers will suffice.
Run Workflow API
Programmatically trigger Amperity workflows including Stitch runs, data orchestrations, and campaigns through a comprehensive API. This capability provides precise control over workflow scheduling and execution, facilitating integration with other enterprise systems such as Databricks, Azure Data Factory, and similar technologies.
Snowflake Bridge - Outbound
Access unified customer data from Amperity directly in your existing Snowflake environment without ETL processes. This native integration uses Secure Data Sharing to make consolidated customer data instantly available in Snowflake, maintaining a single source of truth and building your customer data foundation.
Complex Types in Source Data
Upload your raw, unstructured customer source data- including complex field types like arrays, structs, JSON, or XML- and let our system handle the processing.
Real-Time Tables (Public Preview)
Real-Time Tables let you interact with, and activate on, real-time data as soon as it is sent into Amperity.
new
New Capability
Customer 360 Tab
C360 | Core tables now available in database table run history
Core Tables are now visible in run history for databases. The run history view allows users to get an understanding of when each table in databases were last run, skipped, or failed, and provides a visual indicator of how long the table has run for. Adding Core Tables into the database table run history provides a more complete picture of all table operations that happened within a database run without unexpected gaps.

new
Sources Tab
Platform Update
Amperity Bridge | Snowflake: Inbound Data Sharing now Generally Available
We are pleased to announce that Inbound Bridge sharing from Snowflake to Amperity is now generally available to all customers! You are now able to directly load Snowflake data into Amperity via Secure Data Sharing. This functionality comes with a number of benefits including:
Fast set up
- Users can set up an inbound Snowflake Bridge share within minutes - bypassing the complexity of a legacy courier/feeds configuration.Governance
- Snowflake Secure Data Sharing allows for a true zero-copy experience so you can add or revoke shared assets at any time as you see fit.Scale
- The direct data access provided by Bridge allows for users to get Snowflake tables into Amperity extremely quickly. Once configured, Bridge allows for up to billions of customer records to be synced into Amperity Source tables and available for downstream processing within minutes.
Learn how to start using Amperity Bridge for Snowflake in our documentation.
This Amperity Bridge for Snowflake update is part of our larger Customer Data Cloud announcement. Read more about it here.
new
New Capability
DataGrid
Queries Tab
Queries | Spark SQL access in Queries
We are excited to announce Spark SQL availability within the Query Editor for Datagrid Administrators and Datagrid Operators. Now, you can write and test Spark SQL directly in Amperity without running several pieces of the platform. Since Spark SQL is used throughout Amperity to process data, the ability to run queries using the same query engine means that you get to see the exact same query results that Amperity will see when running jobs, saving you time and toil.
Presto SQL remains the default engine for querying, but you now have the option of using Spark SQL as your query engine. Using Presto in queries to test SparkSQL was error-prone due to syntax and performance incongruities that were difficult to identify without running and/or failing multiple potentially costly jobs.
To get started, edit any query in the “Queries” tab. You will now have the option to select Spark SQL as your query engine in addition to Presto SQL. To use, simply start a Spark session and begin running Spark queries.



new
New Capability
DataGrid
Workflows Tab
Workflows | Streamlined Workflow Management: New “Configured” Tab & Courier Group Dialog Enhancements
We are excited to share two UI updates within workflows:
- A new “Configured” tab has been added to the Workflows page to consolidate all information about scheduled workflows from the Sources and Destinations pages into one location.
- The courier group workflow dialog has been given a facelift and now includes visibility into configured activations.
New "Configured" tab
The new “Configured” tab lets you immediately see important information about all your configured workflows, such as run status and schedule. This provides at-a-glance visibility into recent failures and timing across different workflows. You’re able to see the last run status of your configured workflows, with a link available to the latest run to help drill down further if need be.
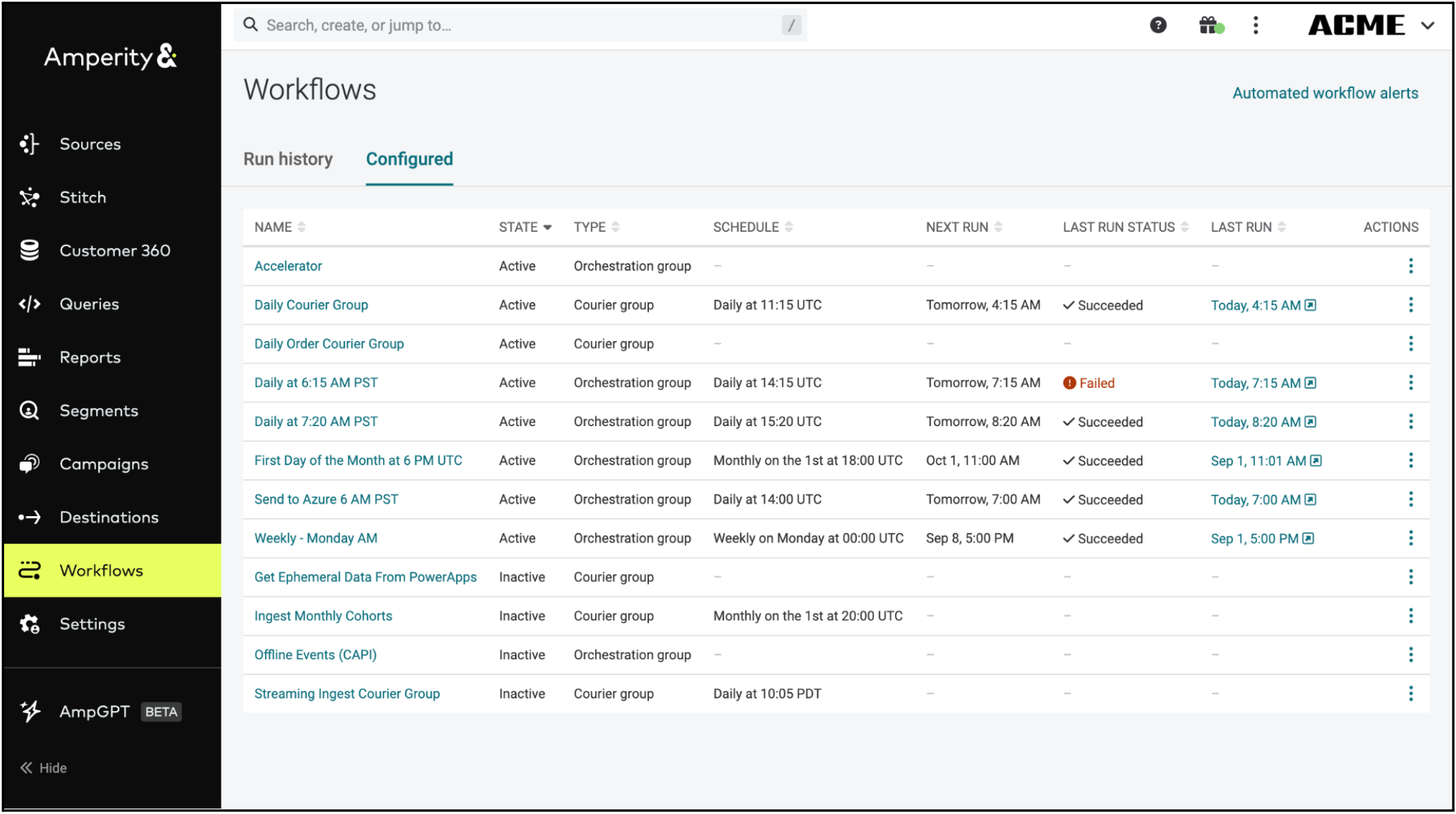
Updated workflow configuration dialog
When you click into a configured courier group workflow, you will also see that the dialog has been given a facelift. All configuration previously available in the courier group dialog is still present, such as general scheduling configuration as well as source data configuration (couriers and Bridges). Previously, however, it was difficult to piece together courier groups with orchestration groups, Profile API indexes, campaigns, or predictive models that had been configured to run as part of a courier group workflow. The new “Activations” tab within the configured workflow dialog lets you see at a glance all of the activations configured to send data downstream as part of a particular courier group workflow. This gives you the full end-to-end picture of what data sources comprise a workflow, and what destinations a workflow will send to.
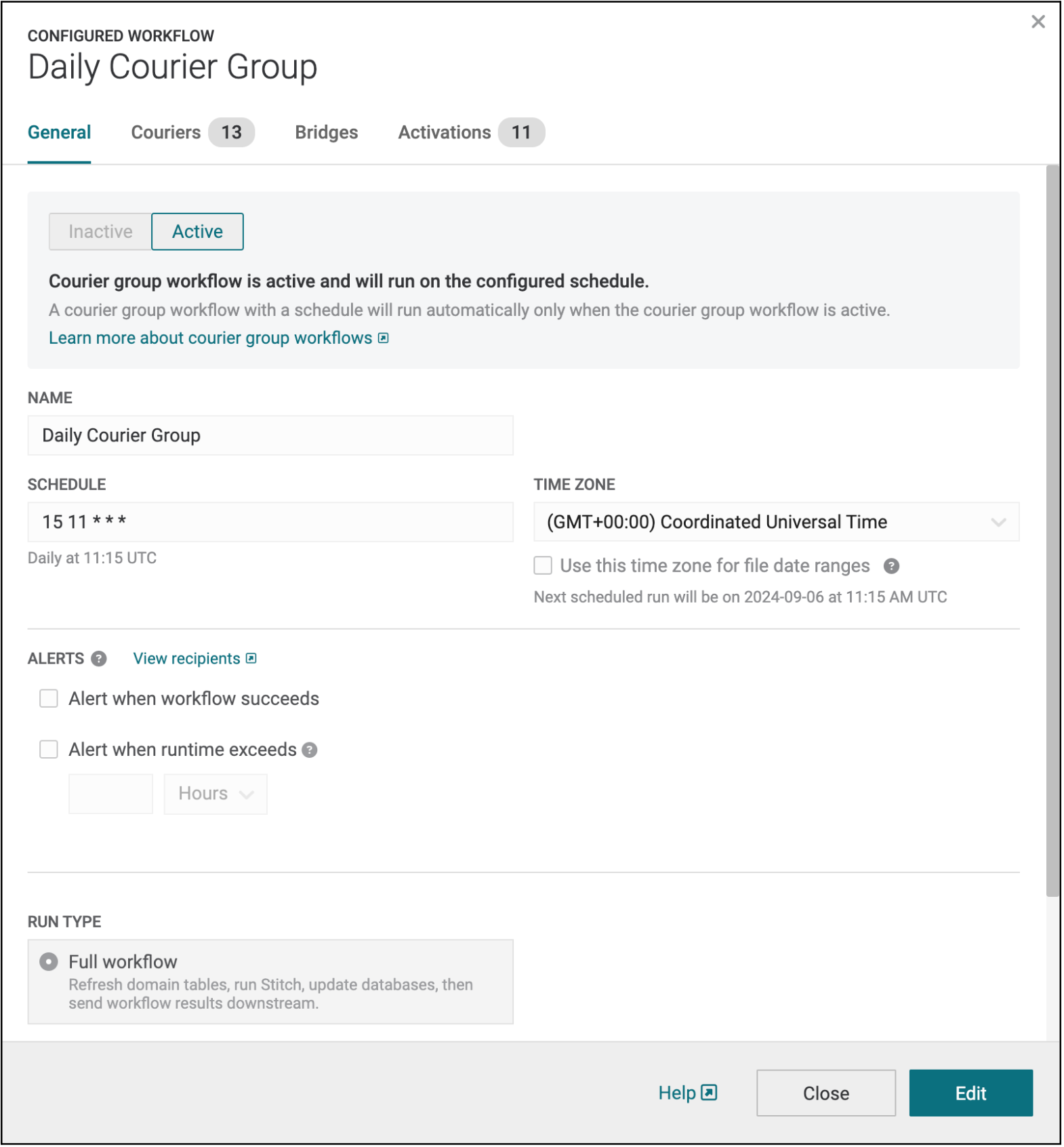
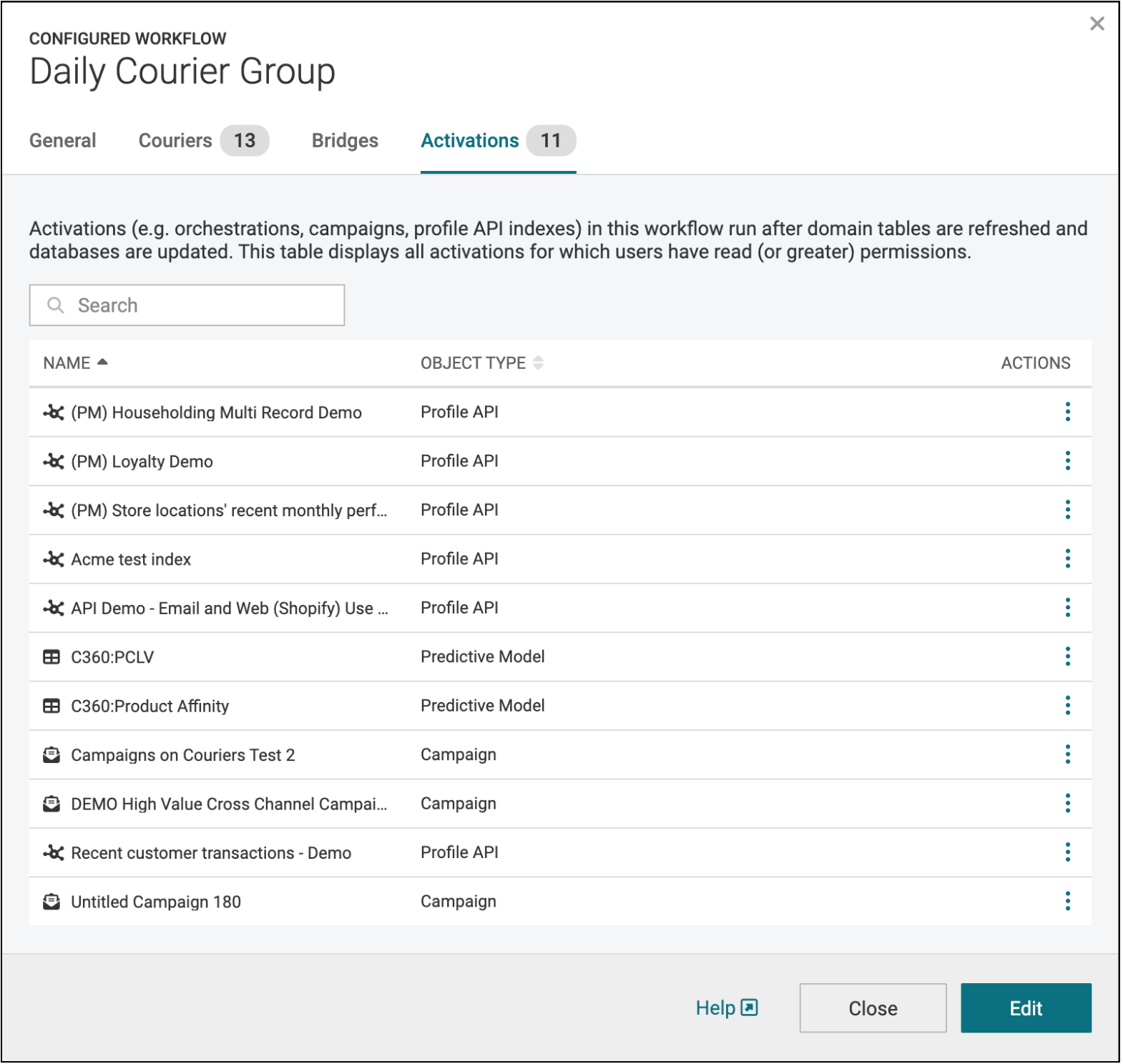
Learn more at our workflow documentation or courier group documentation.
new
AmpIQ
Campaigns Tab
Workflows Tab
Campaigns | Additional alerting options now available
You can now receive alerts when campaigns complete or when campaign runtimes exceed a configured threshold. This lets you know that your campaigns are finished sending or if there are any anomalous runtime issues with your campaigns, without having to watch campaigns in Amperity.
Campaign success and duration alerts are available under “Advanced campaign settings” from the “Automated workflow alerts” dialog in the Workflows page.
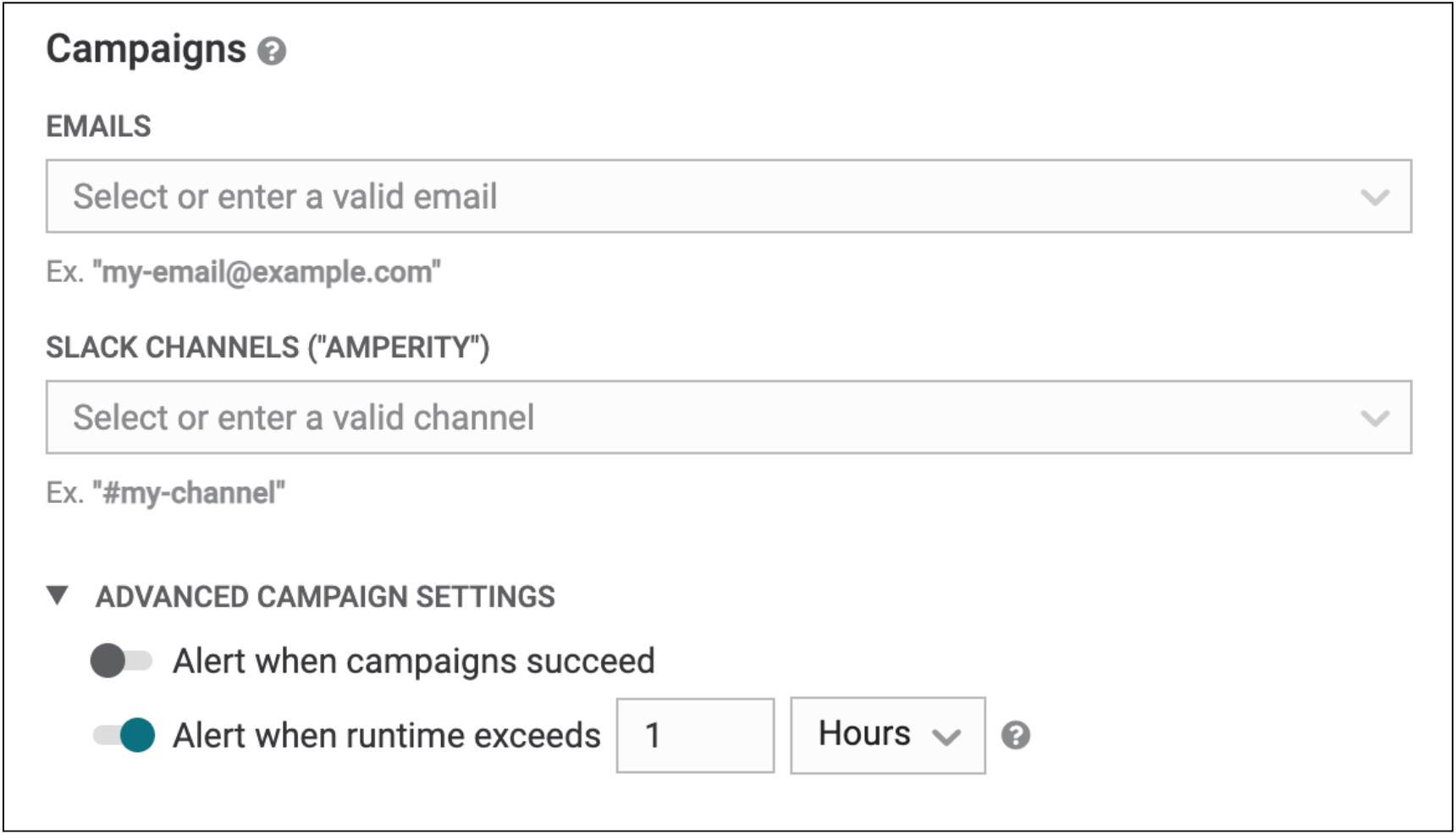
Learn more in the Amperity Documentation.
improved
new
AmpIQ
Campaigns Tab
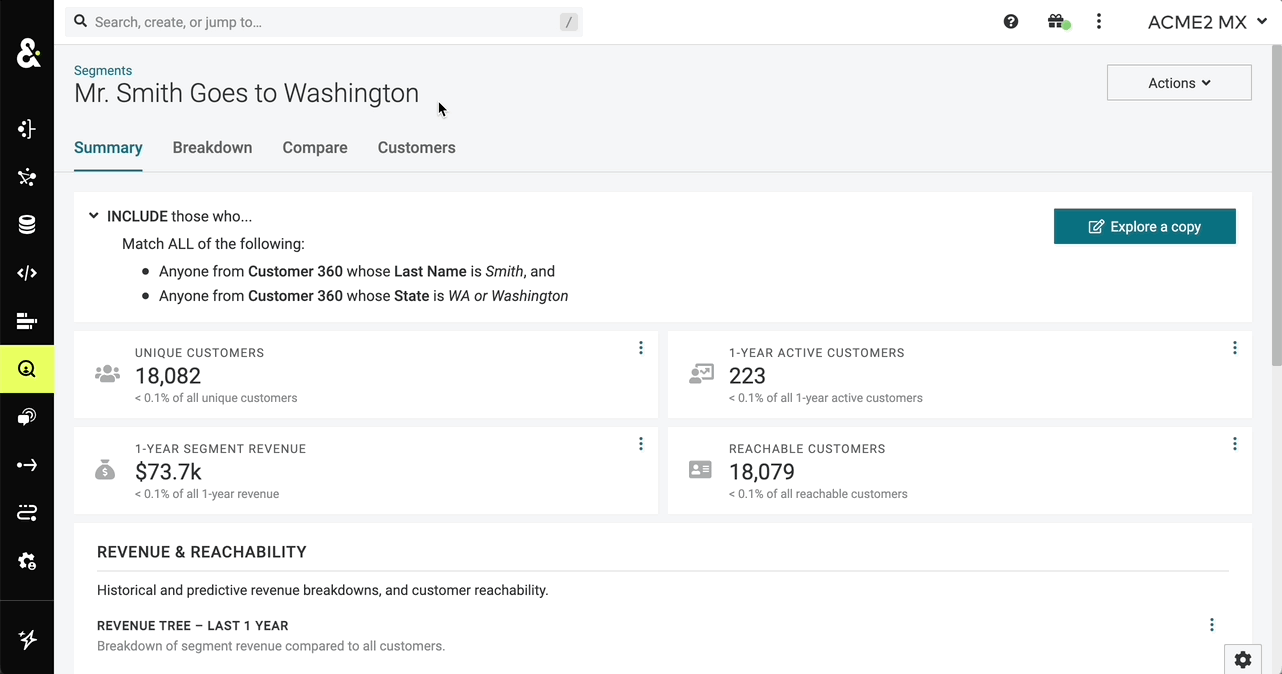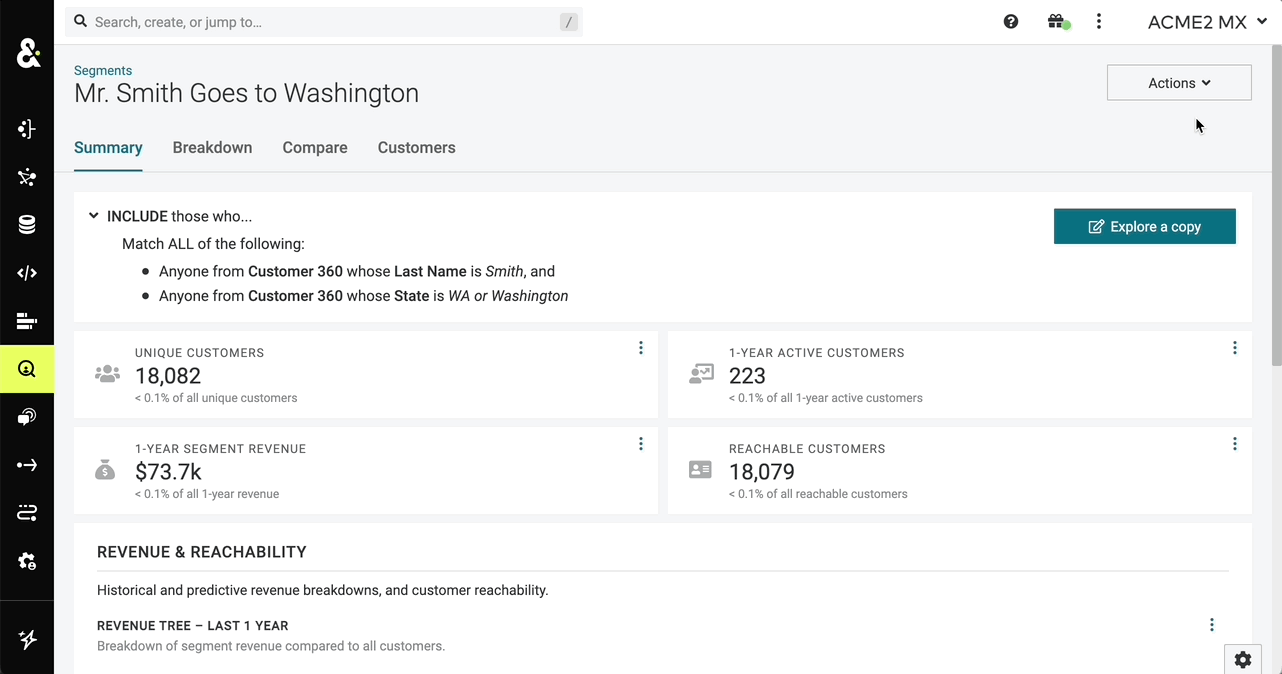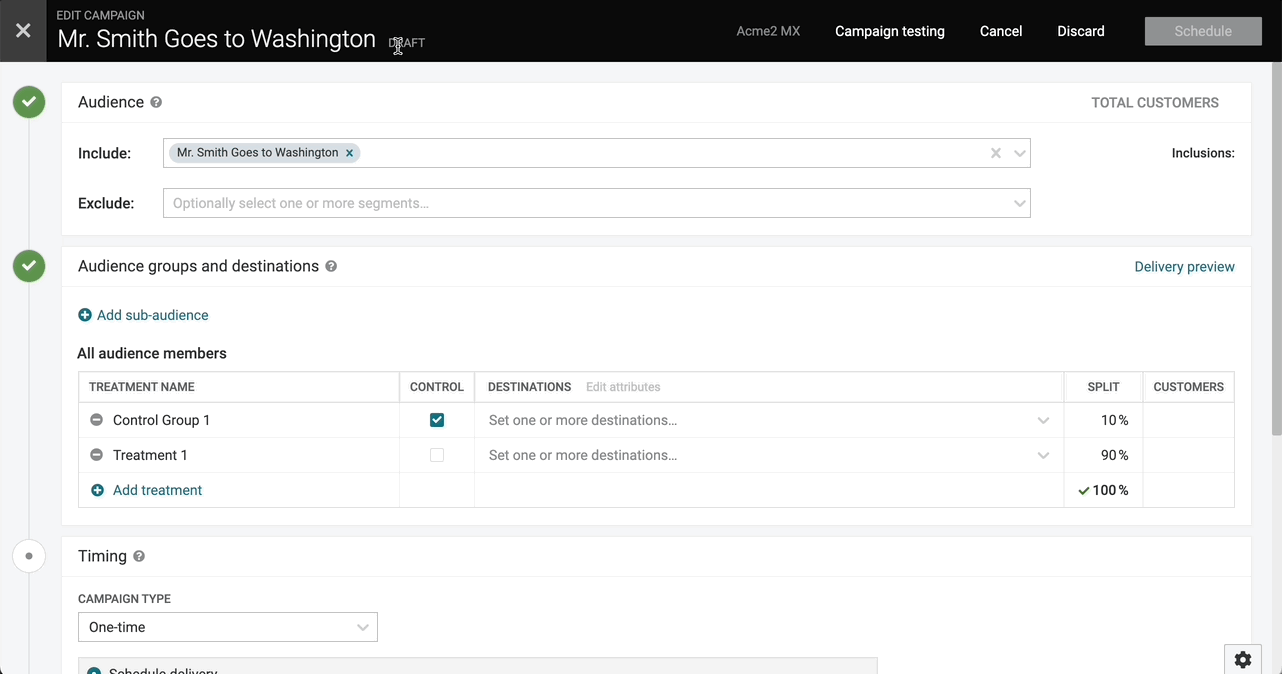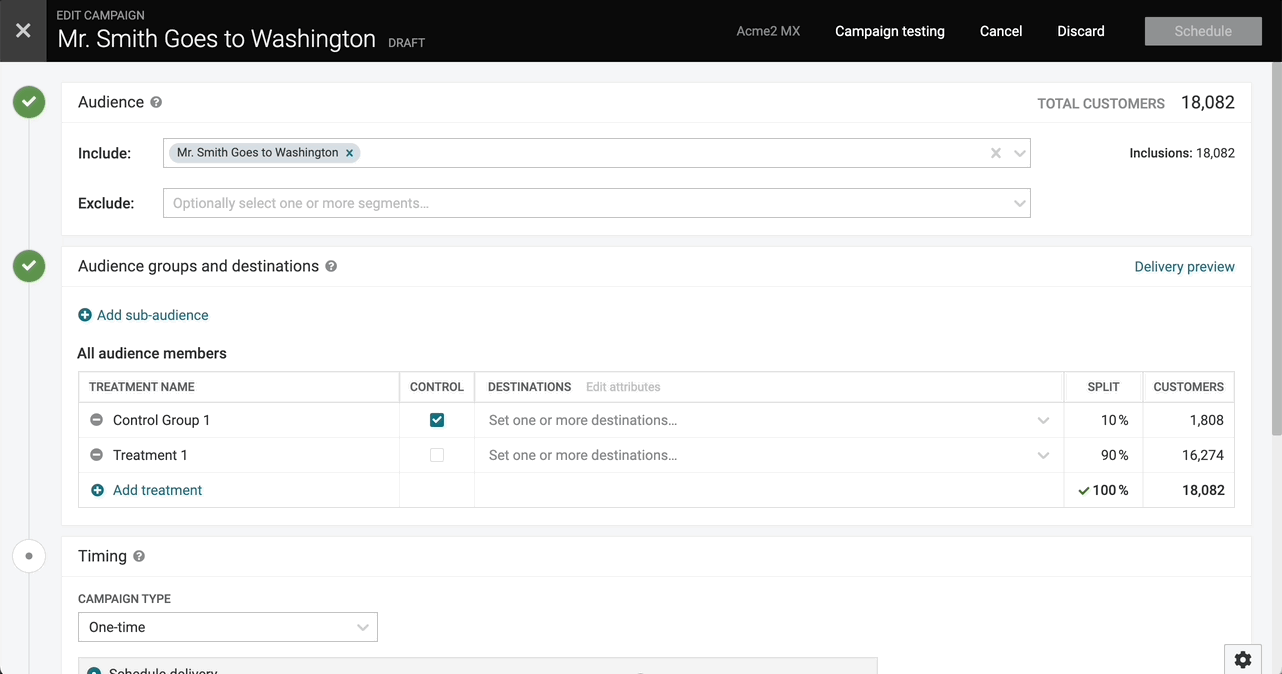
Campaigns | Updates and Improvements
We are excited to announce recent updates to campaigns that make creating, updating, and generally using campaigns easier:
- Send Now
- Recently Used Destinations in Campaign Editor
- Drag-and-Drop Campaign Attributes
- Reset to Default Campaign Attributes
- Link to Segments from Campaign Editor
- Improved Search for Filters
- Auto-Populate Campaign Name with Segment
Send Now
You now have the option to send a campaign right away without changing its schedule. Sending a campaign using the "Send now" option won’t impact your existing schedule. Also, snackbar notifications let you know that the campaign is starting without the need to have the 'Recent Activity' sidebar open.
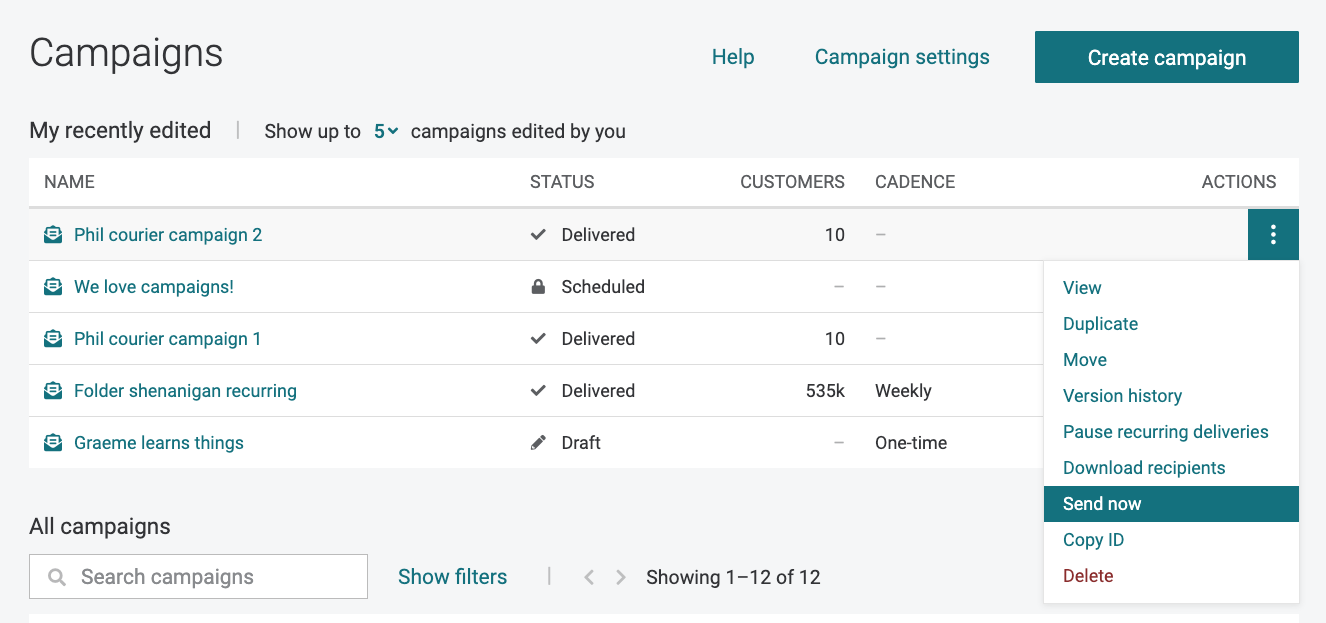
Recently Used Destinations in Campaign Editor
We’ve added a “Recently used” section to the top of the destinations dropdown that pulls the most recently used destinations across all campaigns. As you begin editing, we also add any destinations configured in the current campaign to the top of the list. For the majority of campaigns, the destinations you’re sending to will be right at the top of the list.
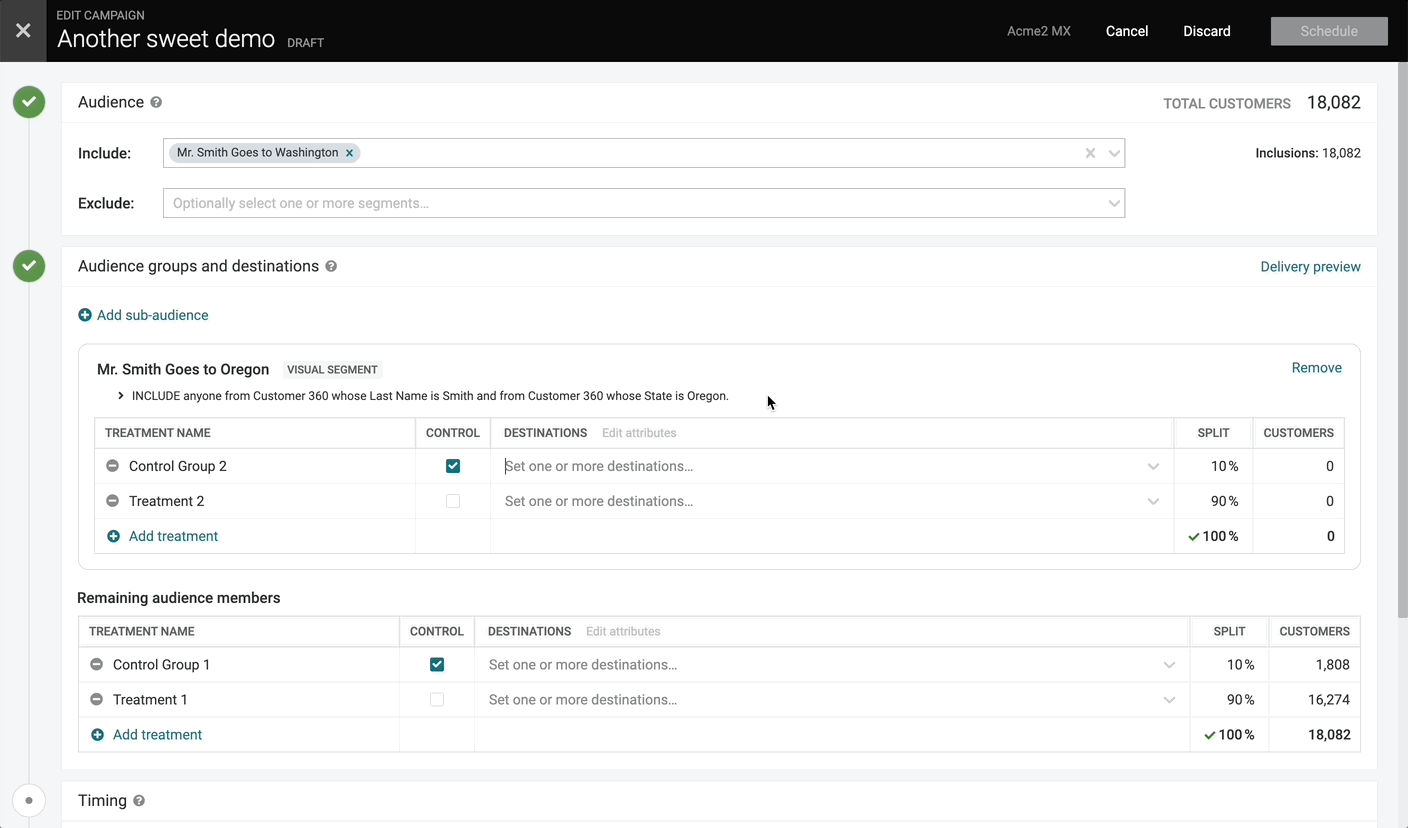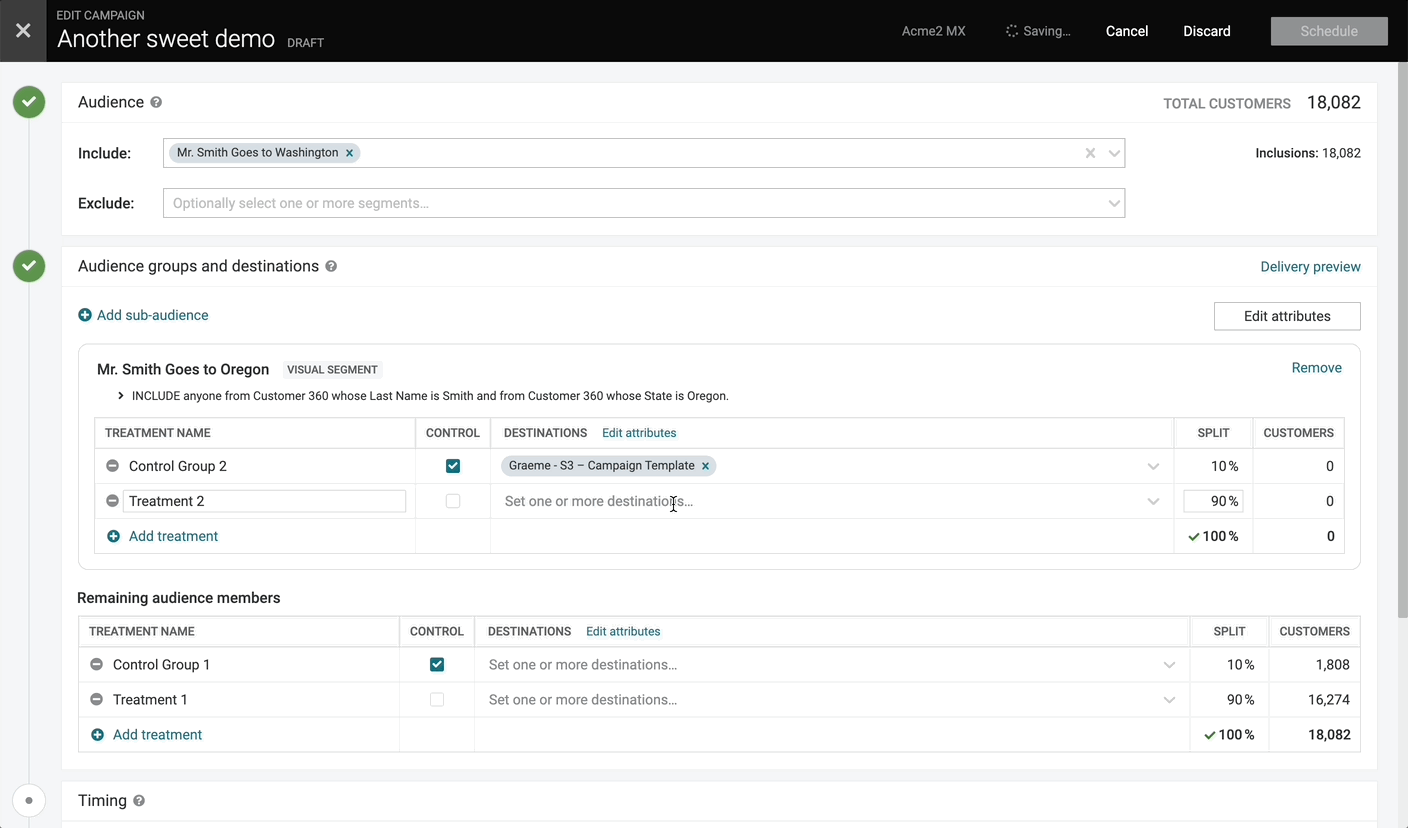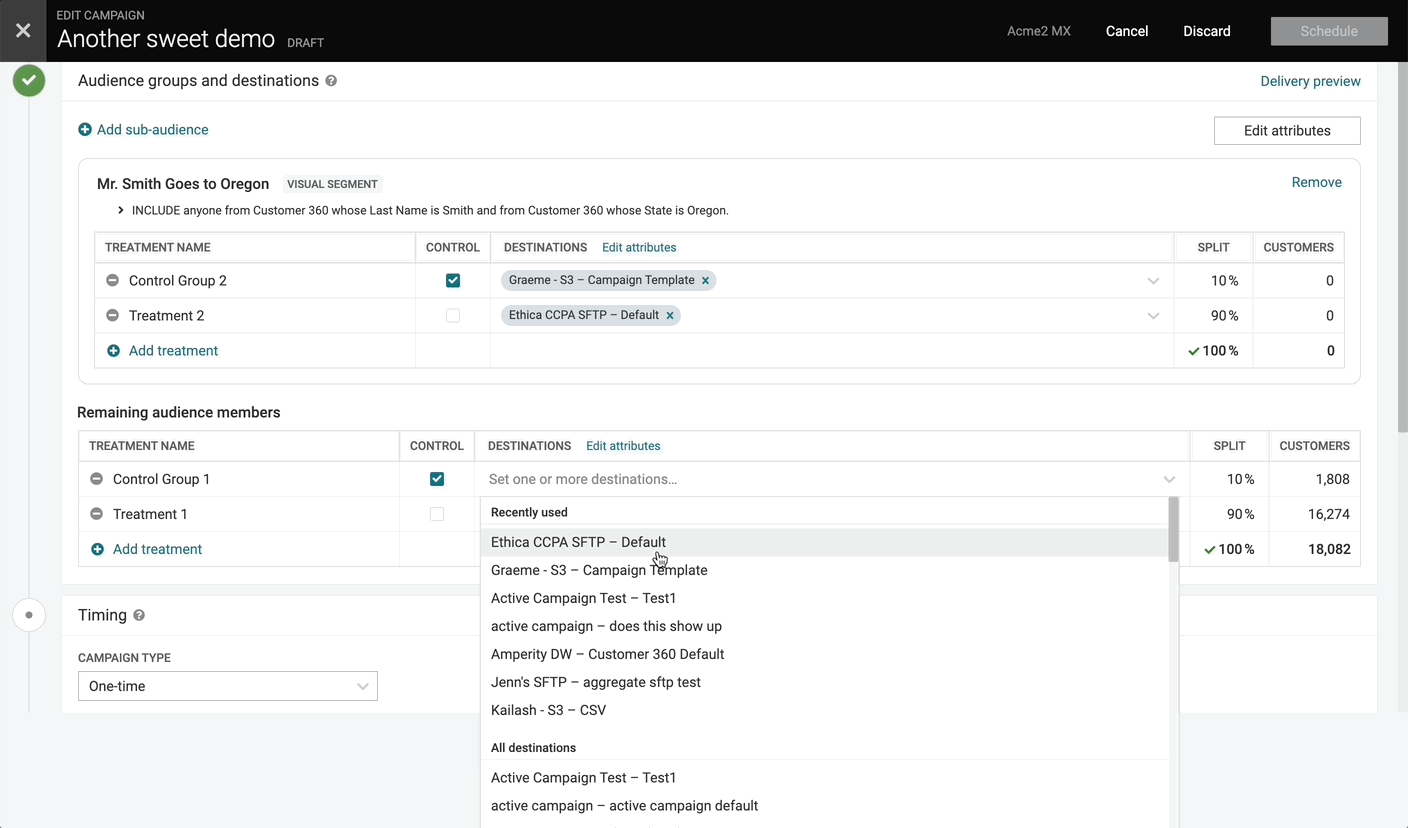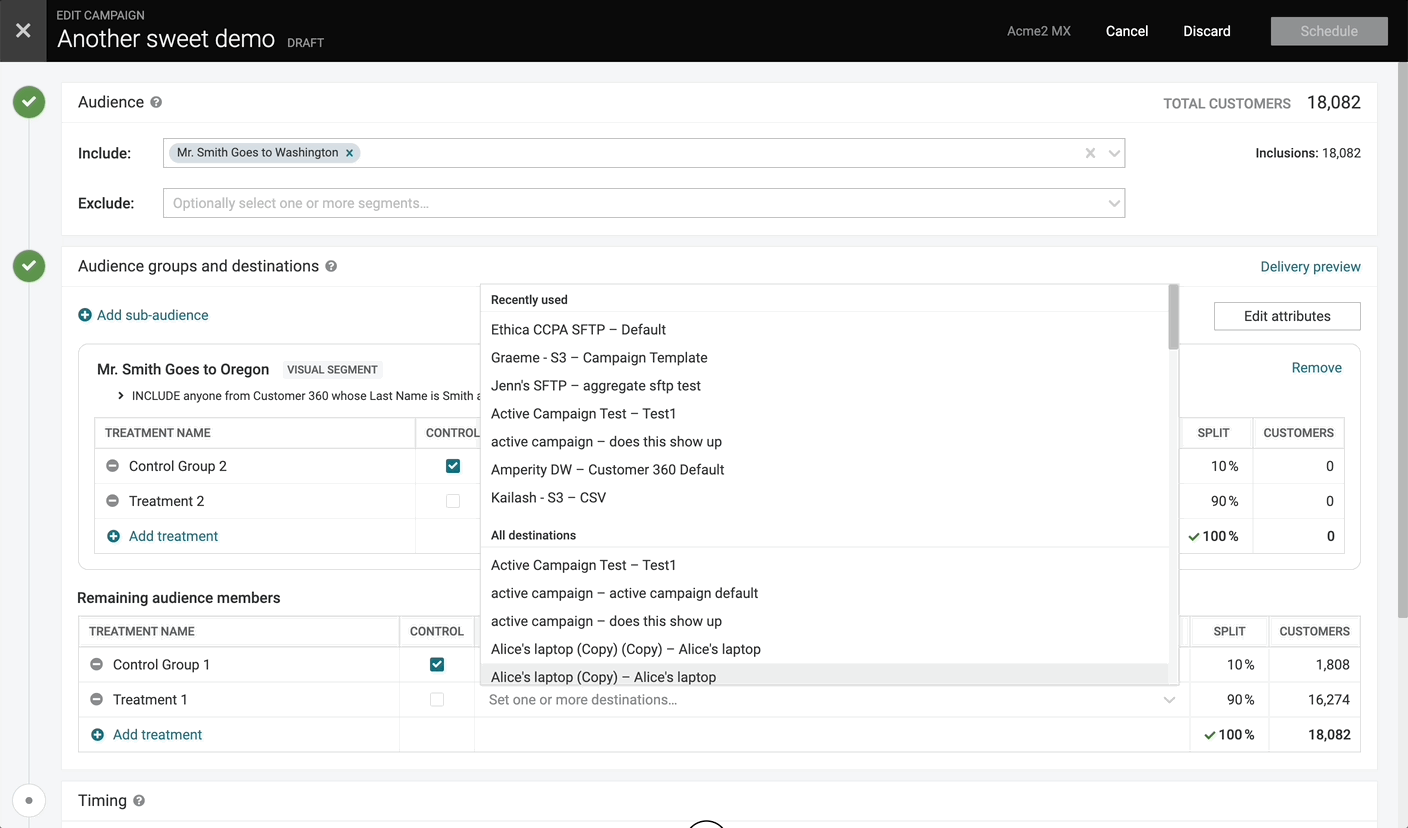
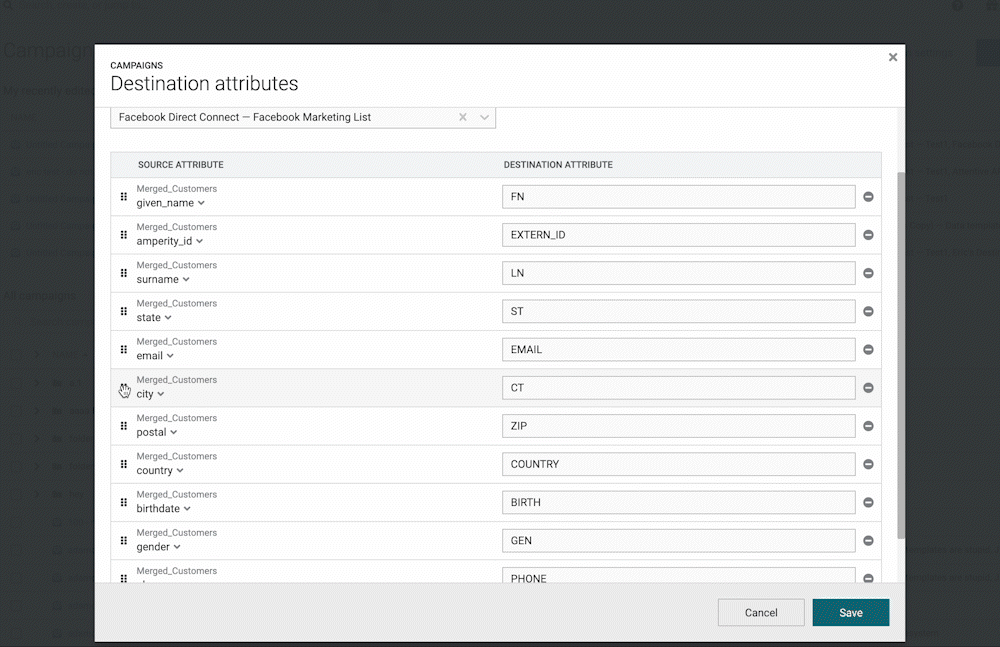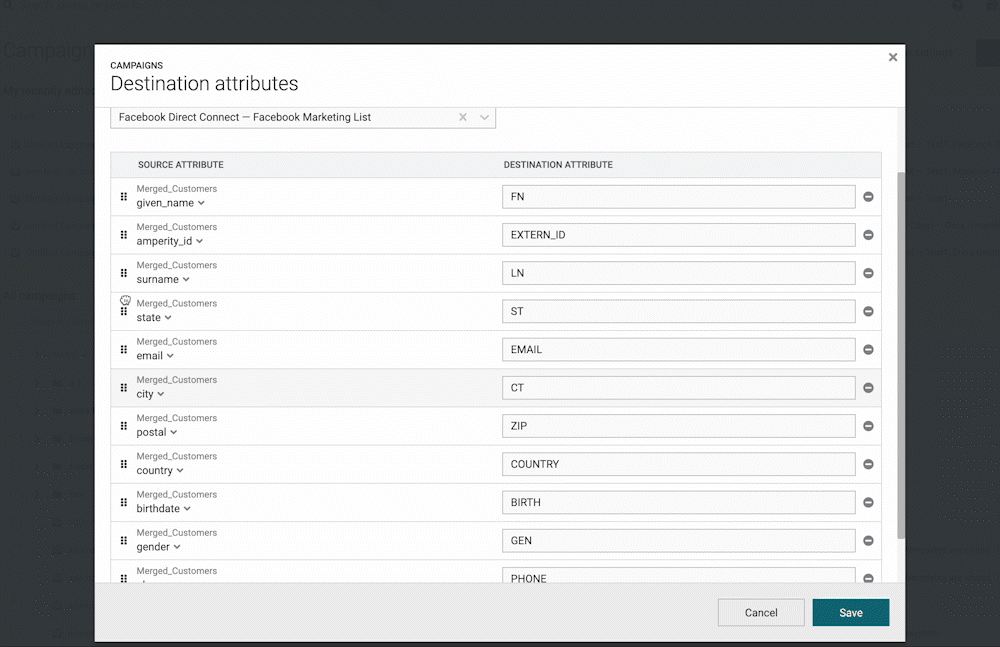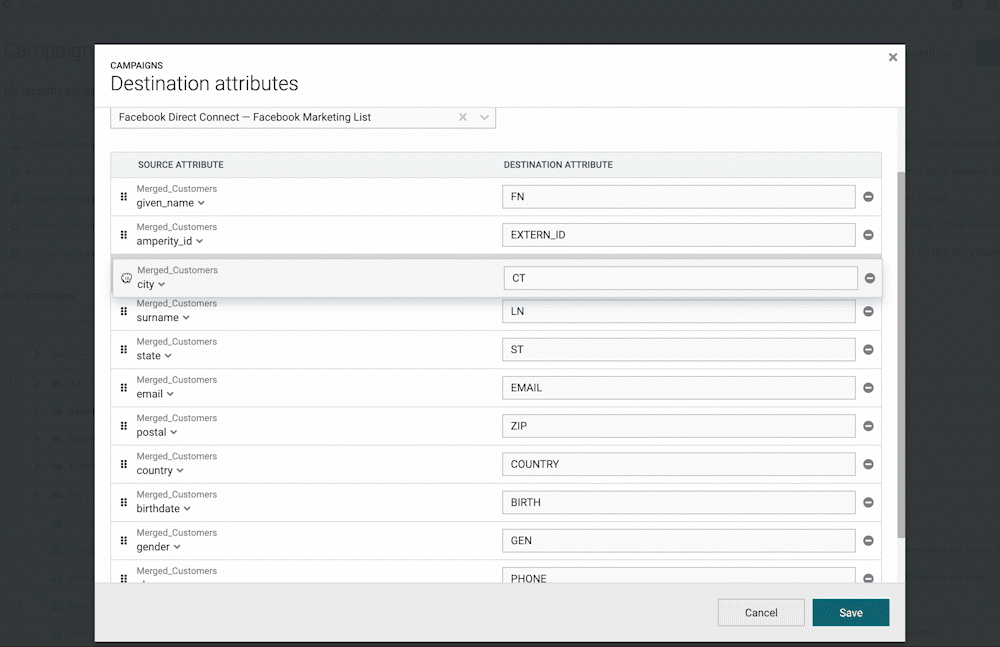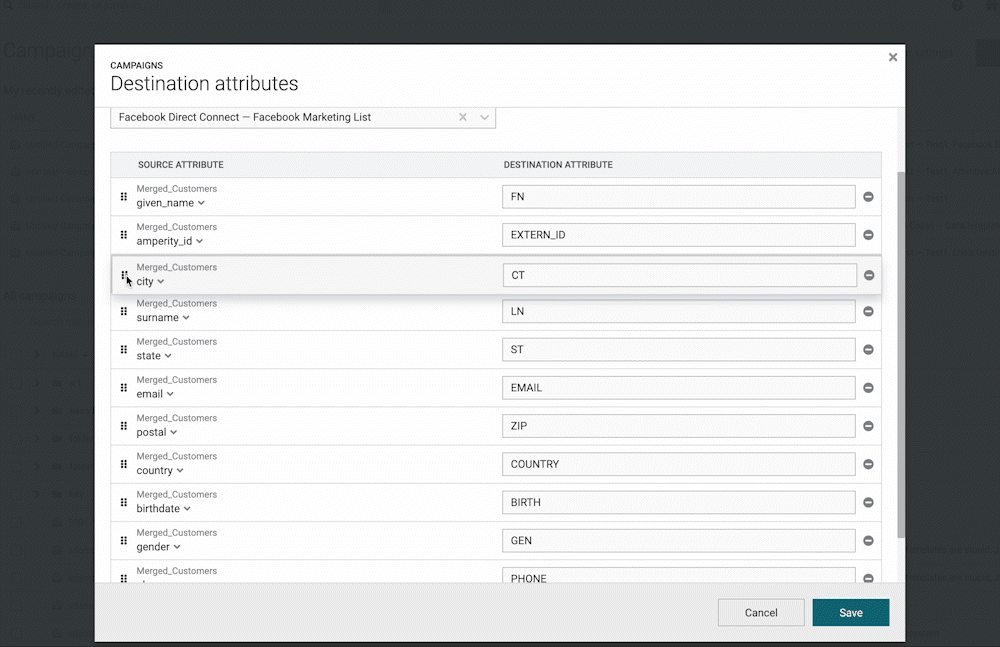
Drag-and-Drop Campaign Attributes
We’ve now introduced the ability to re-order campaign attributes by dragging and dropping the rows in the attribute editor. This allows you to more easily update the order of the fields being sent to downstream systems.
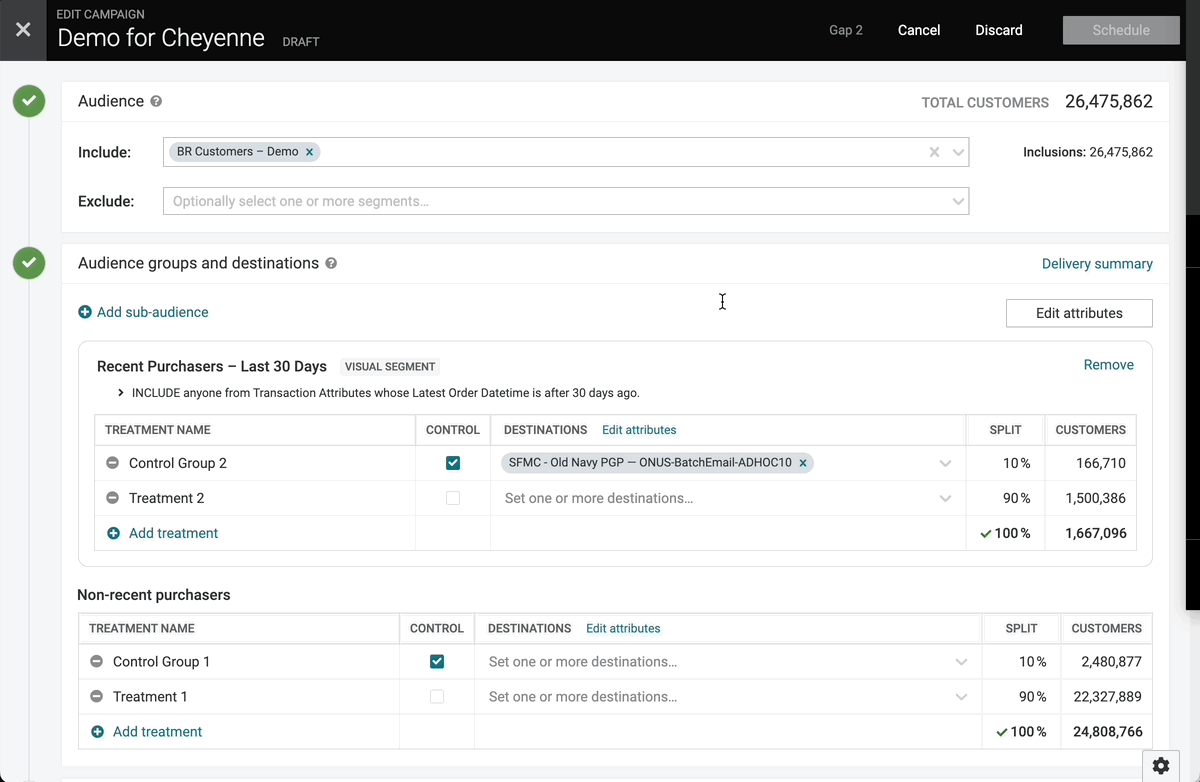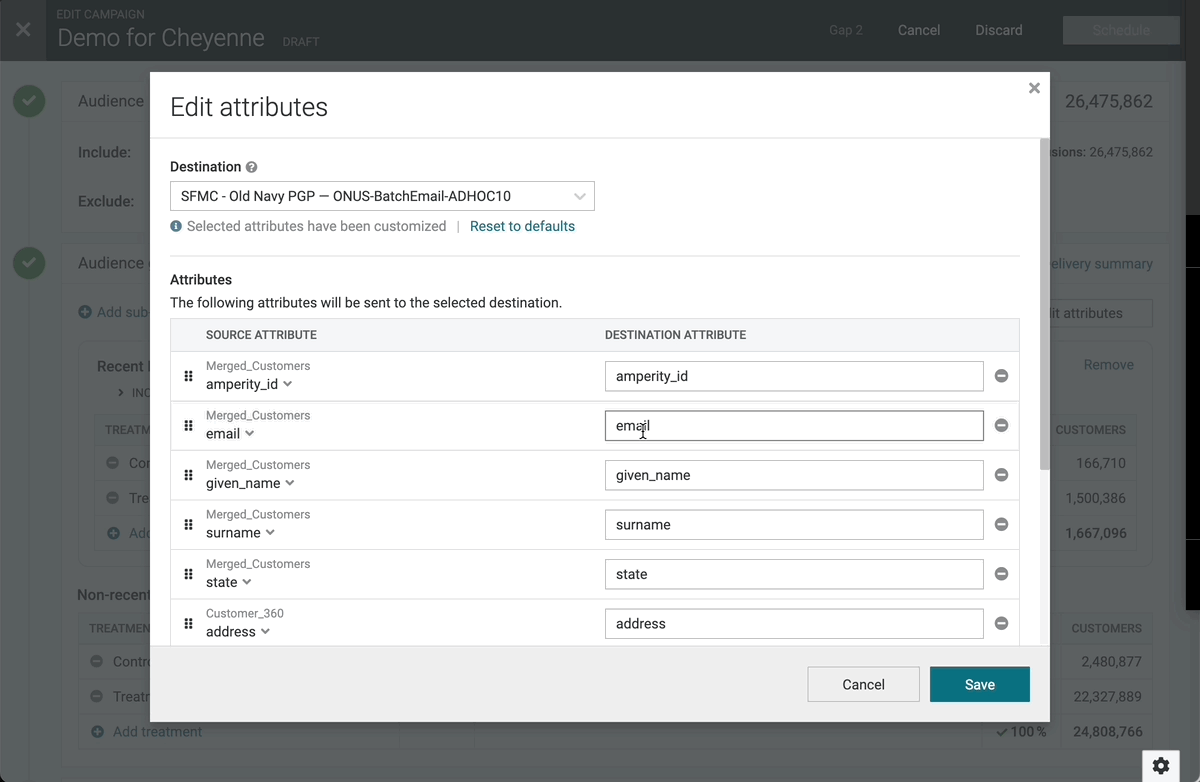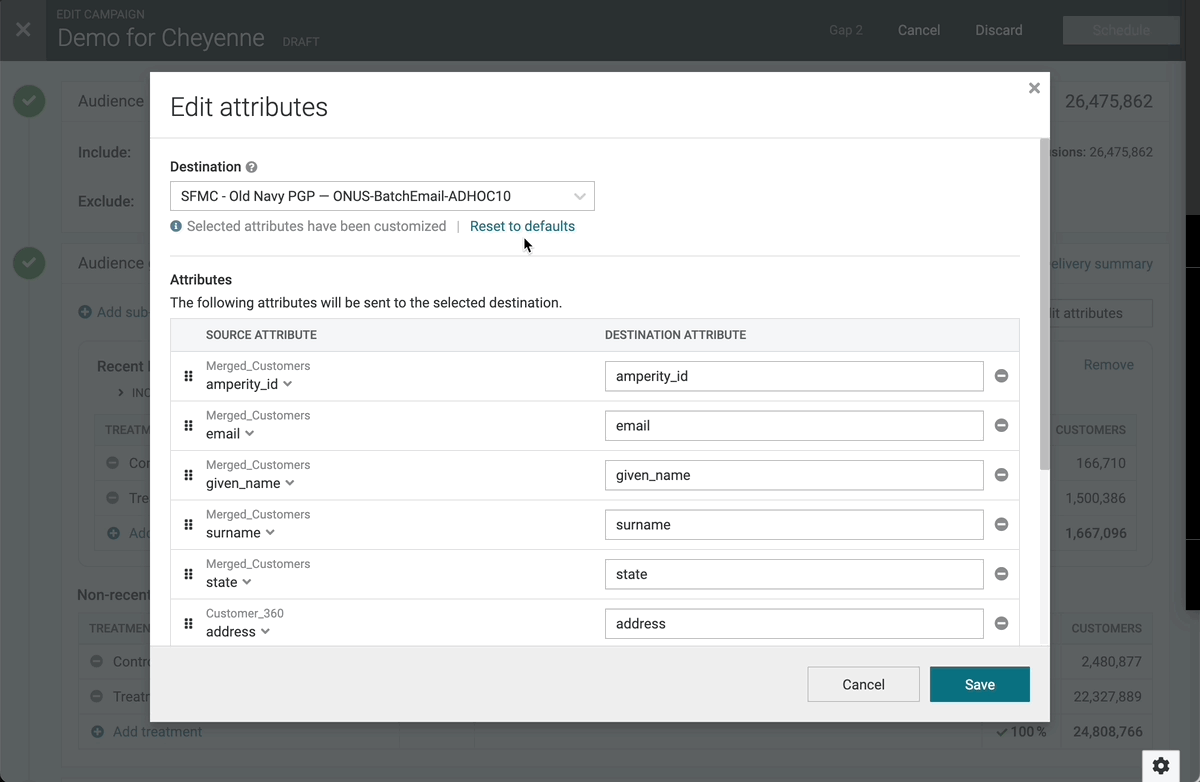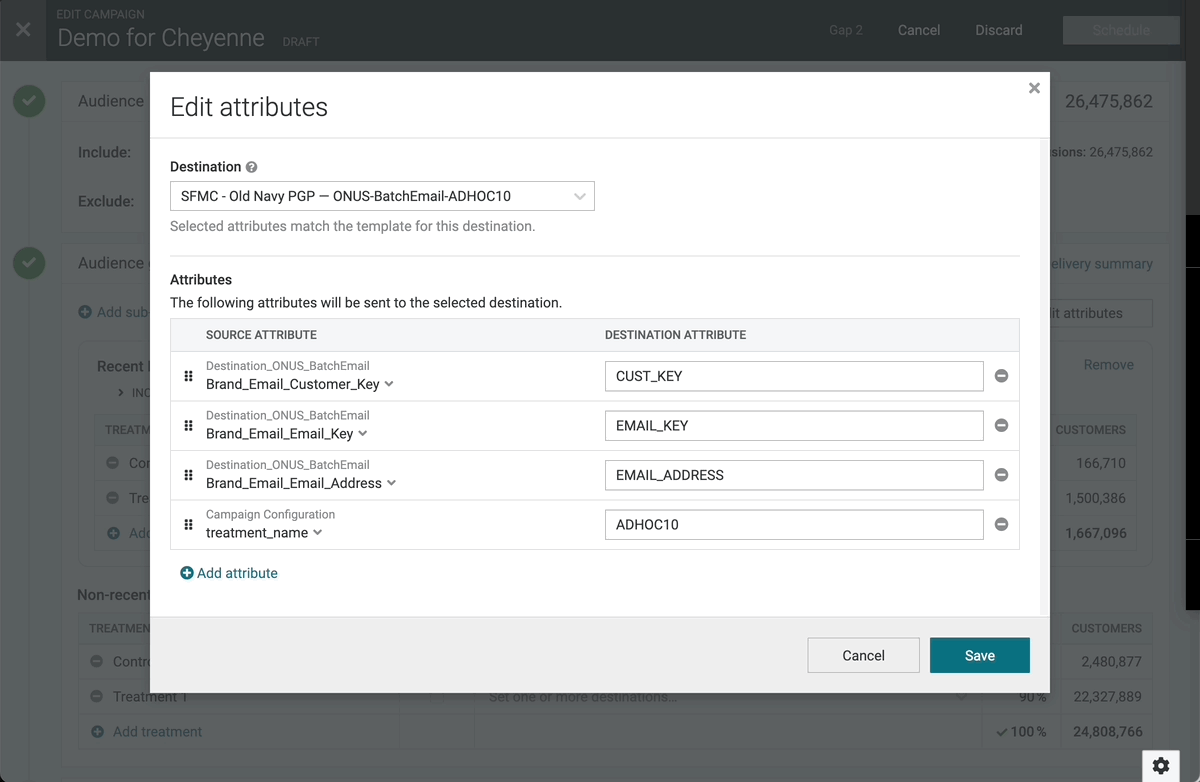
Reset to Default Campaign Attributes
You can now “Reset” the selected attributes for an existing campaign back to the defaults. This is helpful when using campaign attribute templates, which allow users to configure the default attributes that get selected for a given destination when setting up a campaign. While attributes are often unchanged from one campaign to the next, there are times when you might want to reset customized campaign attributes to the default template. Some use cases include:
- If you copy a campaign, any custom attribute configuration gets copied as well. This means that the users “new” campaign may have attributes that are different from the template.
- Attribute templates are only applied at the time of campaign creation, so if the template is updated later, those changes are not automatically applied to the campaign.
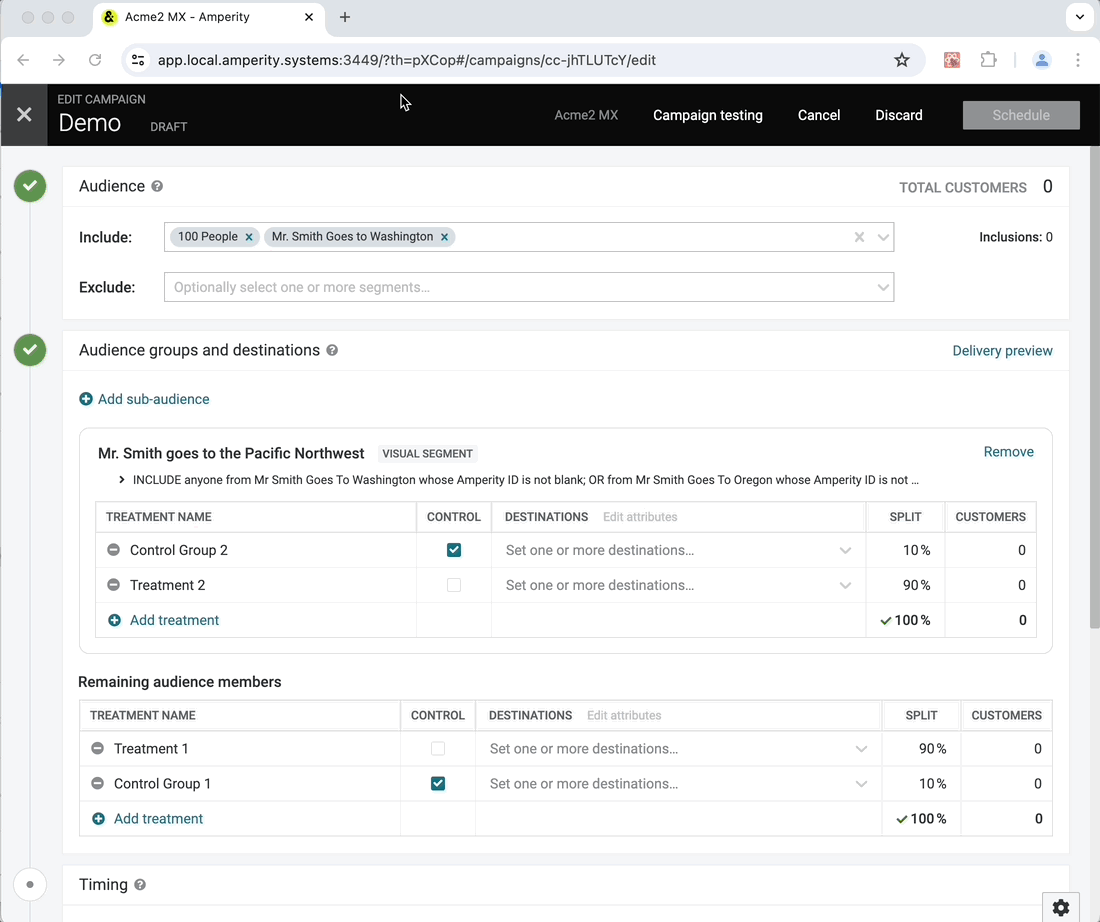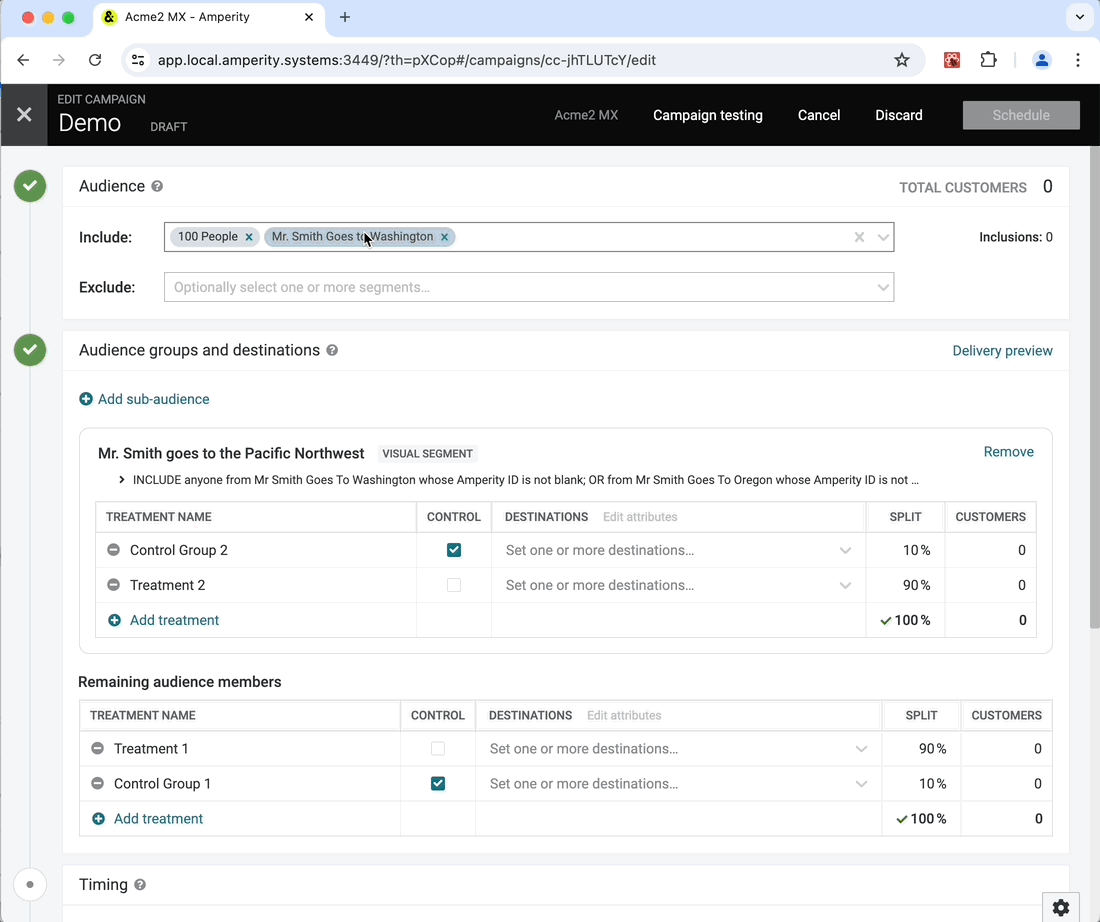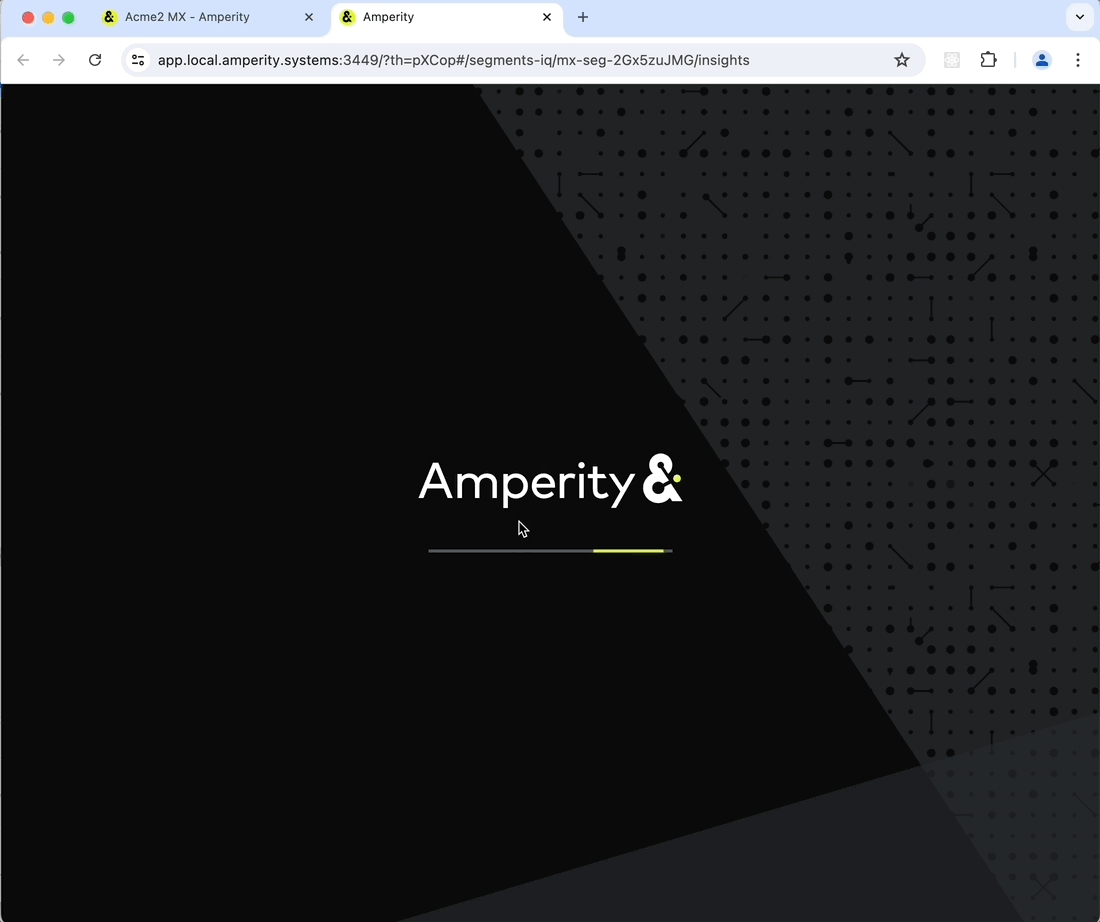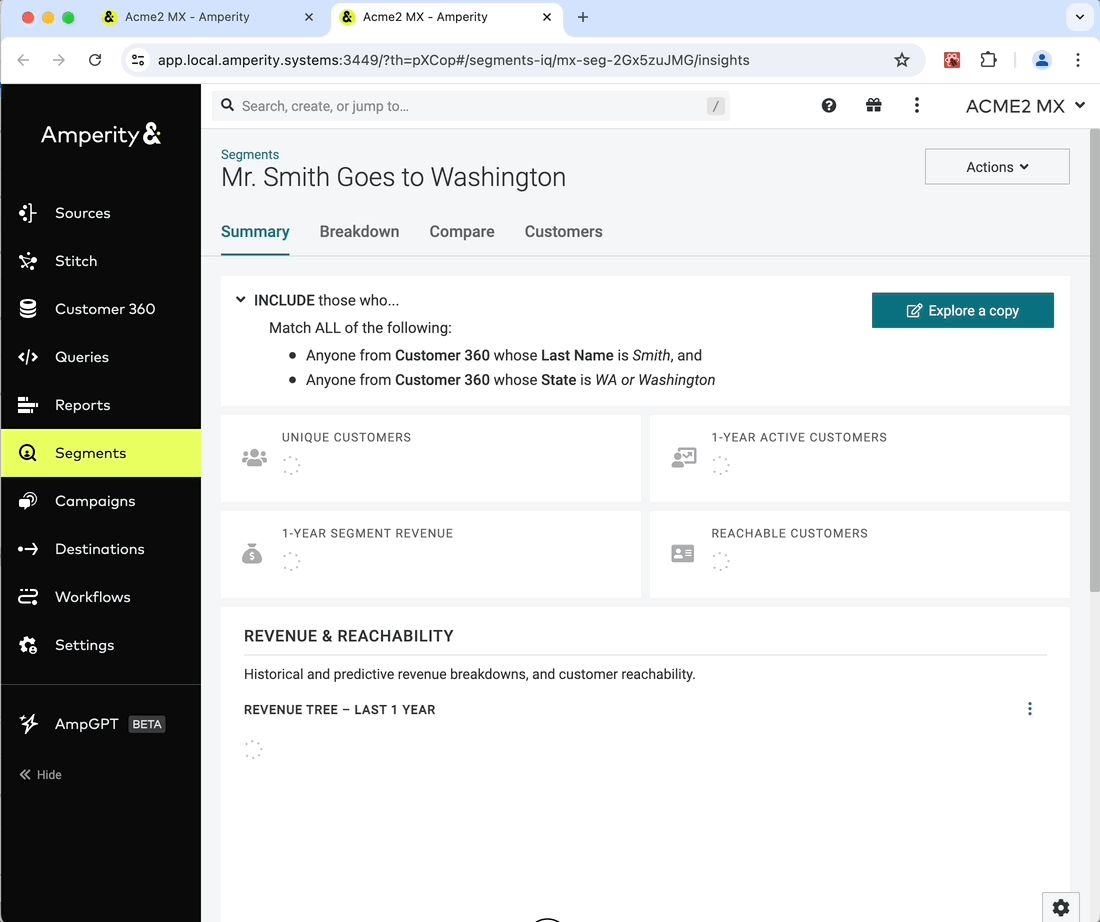
Link to Segments from Campaign Editor
Within the campaign editor, you have the option to select segments for inclusion or exclusion. A user can click on these segments to see the Visual Segment Editor (VSE) criteria or SQL, but they can’t navigate directly to the segment to see any additional information. We have now added a link to the segment insights page, which opens in a new tab so that a user’s current campaign session doesn’t get interrupted.
Improved Search for Filters
The search functionality in the campaigns tab can now be searched by the destination type or destination itself. This change goes beyond just the destinations list and is now true for any filterable attribute. If the filter attributes are grouped, then the search will work over both the individual items in the list as well as their group labels.
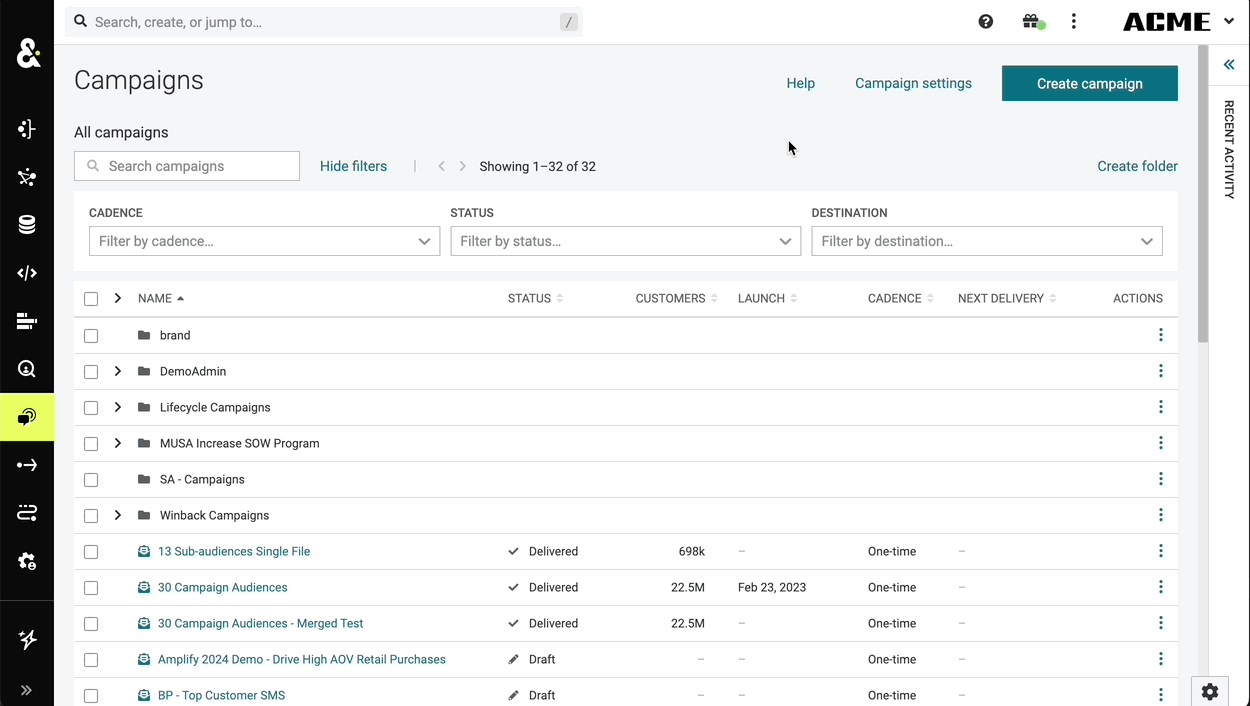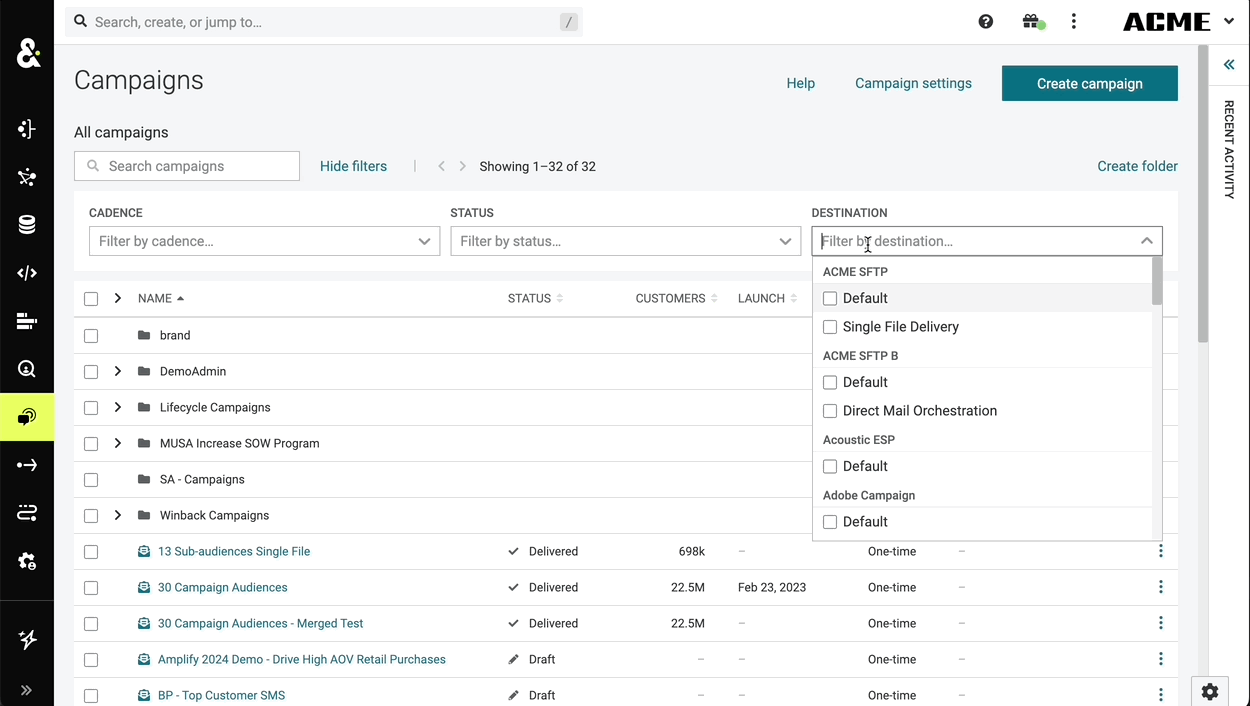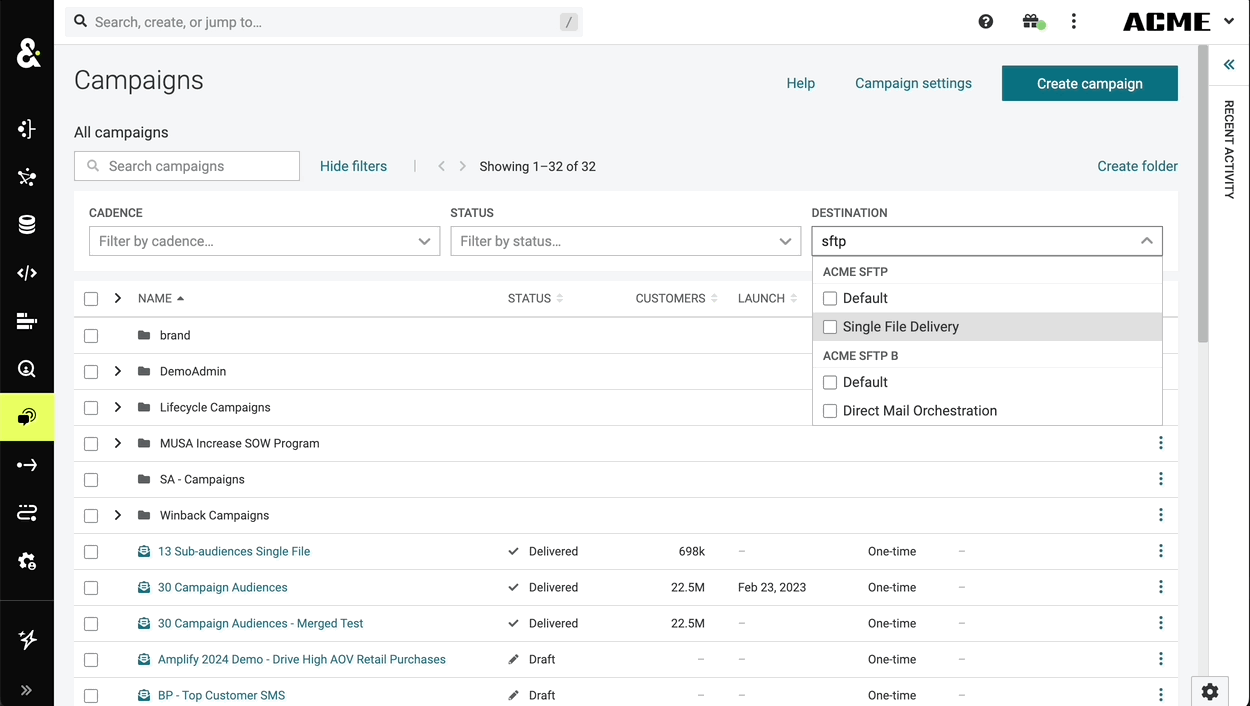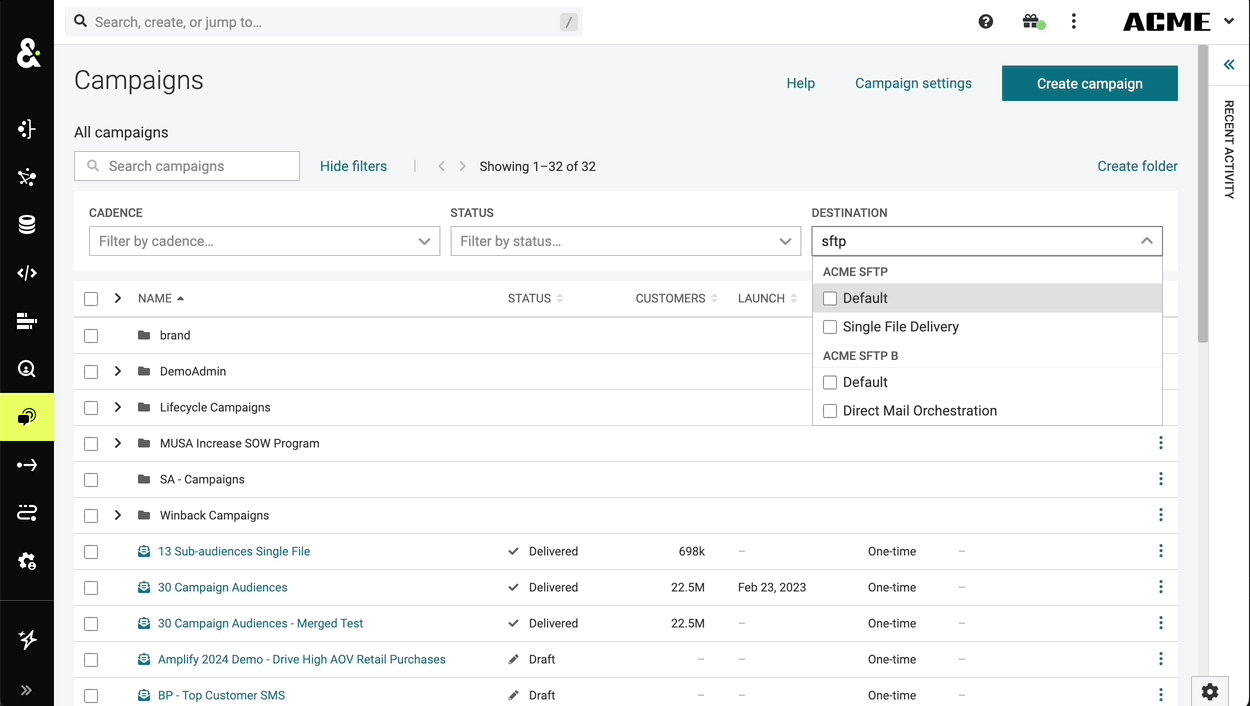
Auto-Populate Campaign Name with Segment
When creating a campaign directly from a segment, the name of the campaign will now default to the original segment name.
Load More
→