improved
DataGrid
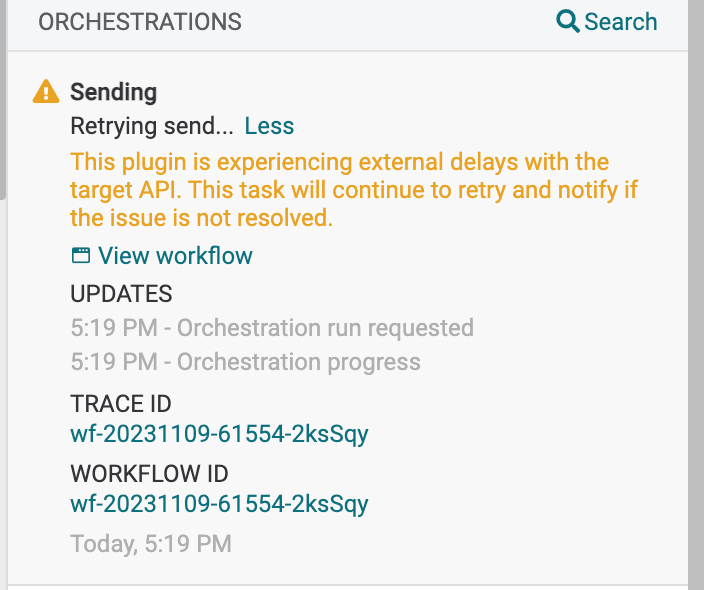
Automatic Retry for Orchestrations
Historically, when we orchestrate data we run into many transient errors, mostly caused by failures outside of the Amperity platform. Examples of these include timeouts with SFTP, rate limits, or errors in external systems. In most cases, these orchestrations would succeed on retry, but we would require you to retry manually via an alert.
To mitigate this, we now retry most common errors by default. There will be a wait time of 10 minutes between retries and we will attempt to retry for up to 2 hours before failing. These timings can be configured for different plugins if required.
To ensure you are informed, while this is happening we display a notification card to let you know things are taking a little longer than expected. While small, this change is already showing great success in improving delivery while reducing the number of manual interventions you have to make.